My research is centered around enabling greater interactivity in High-Performance Computing (HPC). In traditional HPC, large-scale compute resources, such as supercomputers, are shared by many, from hundreds to thousands of users, where each user may attempt to make use of part or even all of the machine for their project. To orchestrate the usage of the machine, these users submit what are referred to as jobs, which can be seen as descriptors which describe the resources required, such as the amount of memory, cores, accelerators, compute nodes, etc. that is needed, how long they are needed for, as well as the actions to take after acquiring said resources. A user’s job is submitted to a job queue for scheduling, upon which their job may not be scheduled to run for many hours, days, or even weeks. This approach towards scheduling on supercomputers, referred to as batch scheduling, has been a well-tested and reliable scheduling scheme for decades and is the standard in the world of HPC. The workloads in HPC, typically scientific computing such as computational simulations and solvers, benefit from the additional compute resources and are generally compute-bound, meaning the runtime is dependent on the amount of compute that is available. Even modern applications such as deep-learning and other neural network training directly benefit from having access to more and more resources.
Problems arise when certain applications have a less-predictable computational pattern, such as for interactive applications. Here, interactivity refers to human interaction, which unlike in the event of large-scale computations, does not strictly benefit from having more resources all of the time and can prove to be wasteful. For example, a user running some complex analysis of a large dataset may require a large amount of memory and compute while processing said dataset. Once said processing is complete, the user may need to perform further analysis on said dataset in some way, such as producing figures or some histogram about the data in question, which requires very little computation in comparison. Then the user may need to analyze the produced figures with their own eyes, leaving the resources idle and unused for an arbitrary period of time (hint: This being an example of a period of human interactivity). Then, after minutes to hours of analysis and hypothesizing, back-and-forth period of compute and human interaction, they may decide to do even more large-scale and complex computation. This, not including the time spent writing the actual code, such as in a Juptyer Notebook, like a data scientist doing Exploratory Data Analysis (EDA) would. This rather dynamic computational usage is not just unpredictable, it even relies on the output of the previous results (i.e. whehter you write more code depends on what you find as a result of analysis following a burst of computation), and so cannot be statically predicted by any algorithm with regards to how it should be scheduled. Batch Processing is very static in nature; you declare, upfront, what resources you need and also how long. Interactive applications are very dynamic in nature; your needs changes and you only know what you need in-the-moment. These two are very incompatible and can result in gross inefficiencies.
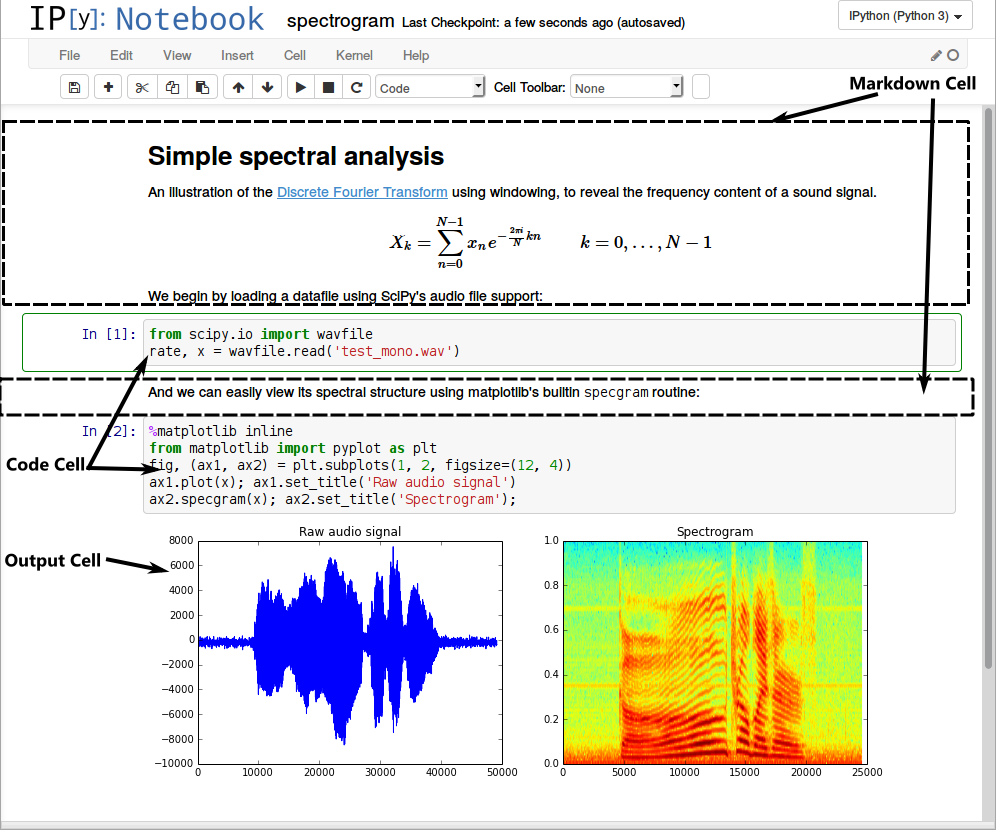
My research centers around Juptyer Notebooks, which are commonly used among data scientists. A Jupyter Notebook allows a programmer to write granular blocks of code called cells. These cells can be executed in arbitrary order, an arbitrary number of times, and at any arbitrary time. New cells can be created and existing cells can be modified at any time by the user. Cells can perform complex calculations or something as simple as displaying a figure. The period of time between the execution of two cells is the idle time, in which any allocation of compute resources would be, by definition, wasteful. An example of a Jupyter Notebook, derived from here can be seen below. Hence, my research is around the design of a scheduler that acts at these notebook cell boundaries which maximizes utilization of resources based on various heuristics, such as the resource usage of a cell based on historical data, and which minimizes turn-around time.